Don't judge yourself by your past. You don't live there anymore.
— Lessons Learned in Life
Don't judge yourself by your past. You don't live there anymore.
我是个受不了安静的人,干活的时候没有音乐不行。我也是欧美音乐fans,多年来积累了不少或热门或冷门的音乐。无奈这些音乐大多没有封面,或者供应商为了节约流量用了压缩的小图,于是在移动设备上显示得惨不忍睹。忍了一段时间后终于忍不住了,亲自改一下。
开始的时候当然是要先找到mp3文件了。使用os.walk递归的查找mp3,把文件名和路径存下来:
import os
def mp3_find(source_path):
mp3_list = []
for root, dirs, files in os.walk(source_path):
map(lambda x: mp3_list.append((root, x[:-4])),
filter(lambda x: x[-4:] == '.mp3', files))
return mp3_list测试一下,放一些mp3文件在test文件夹:
if __name__ == '__main__':
mp3_list = mp3_find(r'test')
print mp3_list接下来要读取mp3的id3信息,我用了eyed3,它不支持python3所以我用的是python2.7
import eyed3,sys
def mp3_load(mp3_path, mp3_name):
try:
id3 = eyed3.load(os.path.join(mp3_path, mp3_name+'.mp3'))
return id3
except IOError:
print ' '.join([mp3_name,'read error.'])
sys.exit(1)测试一下mp3_process:
def mp3_process(mp3_list):
for path, name in mp3_list:
id3 = mp3_load(path, name)
print ' '.join(map(str,
[id3.tag.title,id3.tag.artist,id3.tag.album]))
if __name__ == '__main__':
mp3_process(mp3_find(r'test'))得到名字之后就要从网络抓取图片,这里使用了豆瓣音乐Api v2,参看音乐的返回格式,默认返回到是小图spic来的,手动改成大图lpic。这里使用了比较肮脏的手段去除ident的标点符号。
import json,re
def search(ident):
ident = ident.translate(string.maketrans(string.punctuation,
' '))
url = r'http://api.douban.com/v2/music/search?q=' + ident
mp3_json = json.load(urllib2.urlopen(url), encoding="utf-8")
try:
if mp3_json['count'] > 0:
return re.sub(r'/spic/', r'/lpic/', mp3_json['musics'][0]['image'])
except (KeyError, ValueError): pass
return False有的mp3可能没有id3标签,所以如果search返回False的话还要按文件名搜一遍。修改mp3_process测试一下
def mp3_process(mp3_list):
for path, name in mp3_list:
id3 = mp3_load(path, name)
img = search(' '.join(map(str,
[id3.tag.title,id3.tag.artist,id3.tag.album])))
if not img: img = search(name)
if not img: continue因为我的音乐都是英语的,所以编码用latin1保持最大的可用性,utf-8和utf-16有的移动设备会显示不出封面,注意中文不能使用latin1。
def mp3_burn(id3, img):
id3.tag.images.set(
type=3,
img_url=None,
img_data=urllib2.urlopen(img).read(),
mime_type='image/jpeg',
description=u"Front cover")
id3.tag.save(version = (2, 3, 0), encoding = 'latin1')再次修改mp3_process测试一下,这次是最终版了
def mp3_process(mp3_list):
faild_list = []
for path, name in mp3_list:
print '-- %s:' %name
id3 = mp3_load(path, name)
img = search(' '.join(map(str,filter(lambda x: x,
[id3.tag.title,id3.tag.artist,id3.tag.album]))))
if not img: img = search(name)
if img: mp3_burn(id3, img)
else: faild_list.append(name)
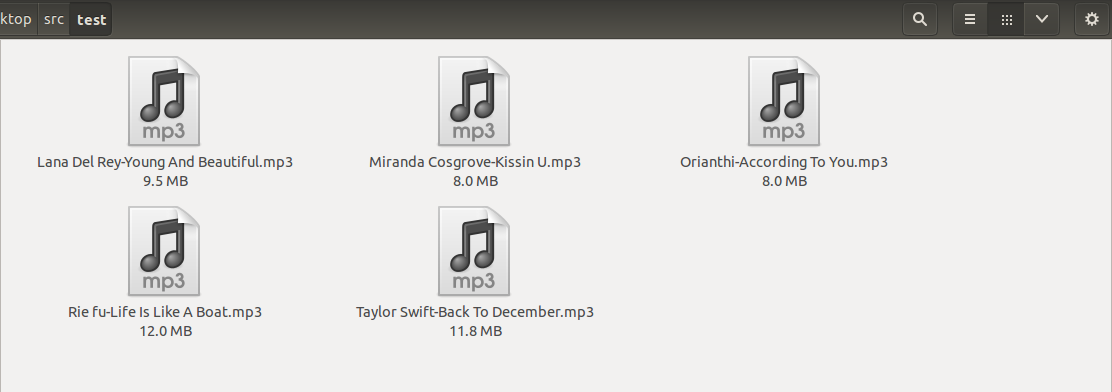
return faild_list随机找来一坨mp3,如图,可以看到是没有封面的。
跑一遍程序,再查看,(ubuntu下不知道怎么刷新缩略图缓存,我是把文件夹复制一份)
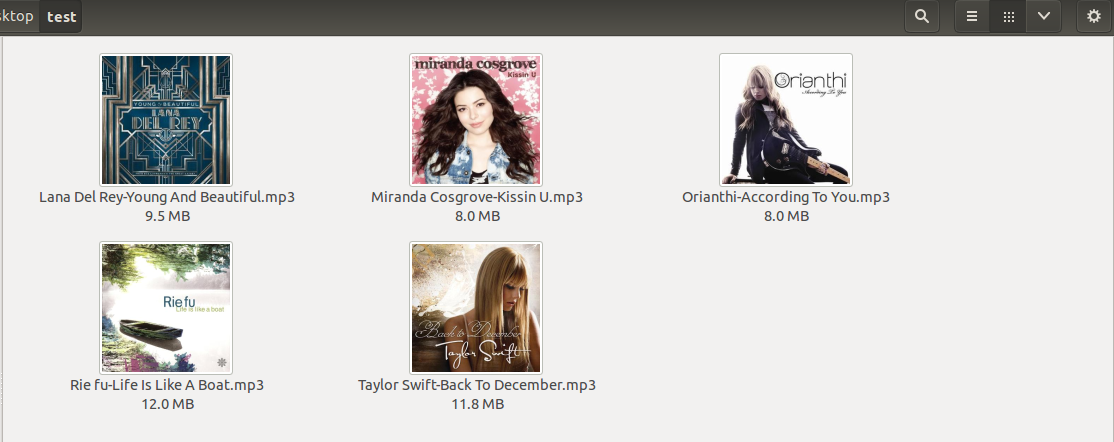
豆瓣的api是有频率限制的,最好申请一个APIKey,或者使用代理,也可以在循环中加入sleep凑合用,一般情况都会没问题。
完整源码在这里。
评论没有加载,检查你的局域网
Cannot load comments. Check you network.